Édition de visage en vidéos avec l’IA !
Vous avez très certainement vu des films comme le récent Captain Marvel ou Gemini Man où Samuel L Jackson et Will Smith semblaient beaucoup plus jeunes. Cela nécessite des centaines, voire des milliers d'heures de travail de la part de professionnels éditant manuellement les scènes dans lesquelles il est apparu. Au lieu de cela, vous pouvez utiliser une simple IA et le faire en quelques minutes.

Exemple de vieillissement. Image tirée du papier.
En effet, de nombreuses techniques vous permettent d'ajouter des sourires, de vous faire paraître plus jeune ou plus vieux, le tout automatiquement en utilisant des algorithmes basés sur l'IA. Ils sont principalement appliqués aux images, car c'est beaucoup plus facile, mais les mêmes techniques avec de petites modifications peuvent également être appliquées aux vidéos, ce qui, comme vous vous en doutez, est assez prometteur pour l'industrie cinématographique. Et au fait, les résultats que vous voyez actuellement, ou dans la vidéo en fin d’article, ont tous été obtenus en utilisant la technique dont je parlerai dans cet article.

Exemple de résultats. Image tirée du papier.
Le principal problème est qu'actuellement, ces images éditées montrant un vieillissement artificiel généré semblent non seulement bizarres, mais lorsqu'elles sont utilisées dans une vidéo, elles auront des problèmes et des artefacts que vous ne voulez sûrement pas dans un film d'un million de dollars. Telles que de petites téléportations ou drôle de bogues dans la peau ou l’arrière-plan. En effet, il est beaucoup plus difficile d'obtenir des vidéos de personnes que des images, ce qui rend encore plus difficile l’entraînement de tels modèles d'IA qui nécessitent autant d'exemples différents pour comprendre ce qu'il faut faire.
D’ailleurs, cette forte dépendance aux données est l'une des raisons pour lesquelles l'IA actuelle est loin de l'intelligence humaine! C'est pourquoi des chercheurs comme Rotem Tzaban et des collaborateurs de l'Université de Tel Aviv travaillent dur pour améliorer la qualité du montage vidéo automatique de l'IA sans nécessiter autant d'exemples vidéo. Ou, plus précisément, améliorez les manipulations faciales basées sur l'IA dans des “vidéos à tête parlante” de haute qualité à l'aide de modèles entraînés avec des images. Il ne nécessite rien d'autre que la vidéo que vous souhaitez éditer, et vous pouvez ajouter un sourire, vous faire paraître plus jeune ou plus vieux. Cela fonctionne même avec des vidéos animées !

Montage de visage sur une vidéo animée. Image tirée du papier.
Les résultats sont extrêmement impressionnants, mais ce qui est encore mieux, c'est comment ils y sont parvenus…
Bien sûr, ce nouvel algorithme utilise des “GANs” ou des réseaux antagonistes génératifs. Je n'entrerai pas dans le fonctionnement interne des GANs puisque je l'ai déjà couvert dans un article que vous pouvez lire ici, mais nous verrons en quoi cela est différent d'une architecture GAN de base. Si vous n'êtes pas familier avec les GAN, prenez juste une minute pour lire l'article et revenez, je serai toujours là à vous attendre, et je n'exagère pas. L'article prend littéralement une minute pour avoir un aperçu de ce que sont les GAN !
Faisons juste un petit rafraichissement pour la partie où vous avez un modèle génératif qui prend une image, ou plutôt une version encodée de l'image, et change cet encodemment pour générer une nouvelle version de l'image en modifiant, si possible, des aspects particuliers. Contrôler la génération est la partie difficile du processus, car il y a tellement de paramètres faisant en sorte qu’il est vraiment difficile de trouver quels paramètres sont en charge de quoi et de tout démêler pour ne modifier que ce que vous voulez.
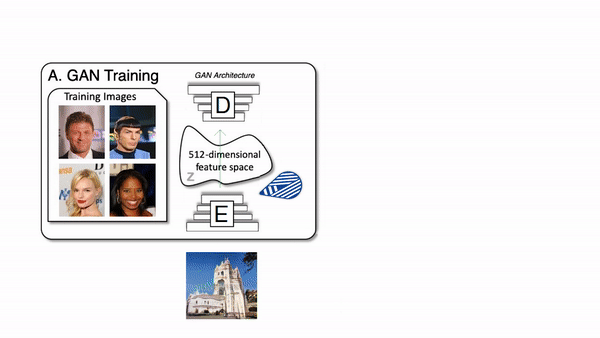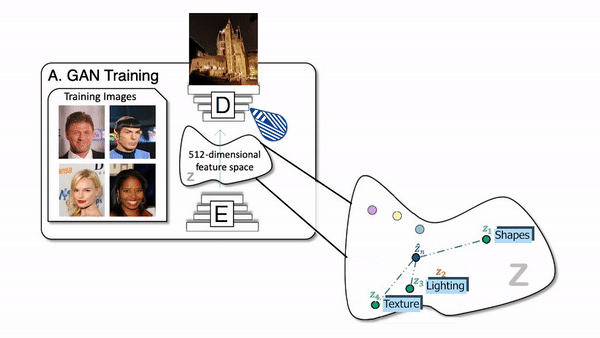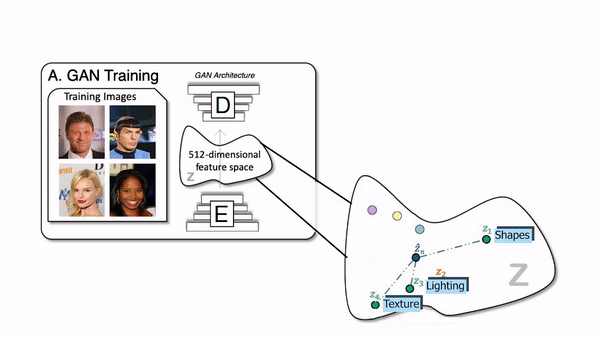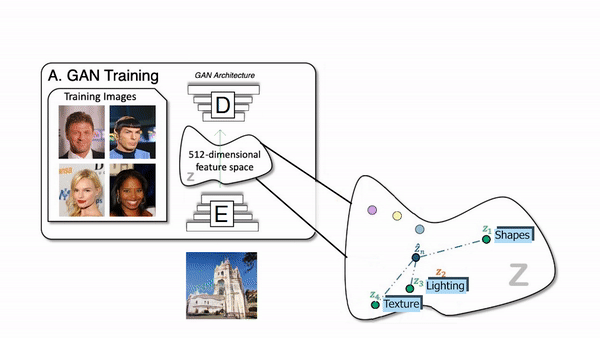
Comment fonctionne le générateur d'un réseau GAN.
Les chercheurs ont donc utilisé n'importe quelle architecture générative, telle que StyleGAN dans ce cas. Qui est tout simplement une architecture GAN très puissante pour les images de visages publiée par NVIDIA il y a quelques années avec des résultats toujours très impressionnants et des versions plus récentes. Mais le modèle génératif lui-même n'est pas si important, car il peut fonctionner avec n'importe quelle architecture GAN que vous pouvez trouver.
Et, oui, même si ces modèles sont tous formés pour les images, ils s'en serviront pour faire du montage vidéo ! En supposant que la vidéo que vous enverrez est déjà réaliste et cohérente, ils se concentreront simplement sur le maintien du réalisme plutôt que sur la création d'une vraie vidéo cohérente comme nous devons le faire dans le travail de synthèse vidéo, où nous créons de nouvelles vidéos à partir de rien, ce qui est bien plus complexe.
Ainsi, chaque image sera traitée individuellement, au lieu d'envoyer une vidéo entière et d'attendre une nouvelle vidéo en retour. Cette hypothèse rend la tâche beaucoup plus simple, mais il y a d’autres défis à relever, comme le maintien d'une vidéo aussi réaliste où chaque image passe couramment à la suivante sans problèmes apparents.
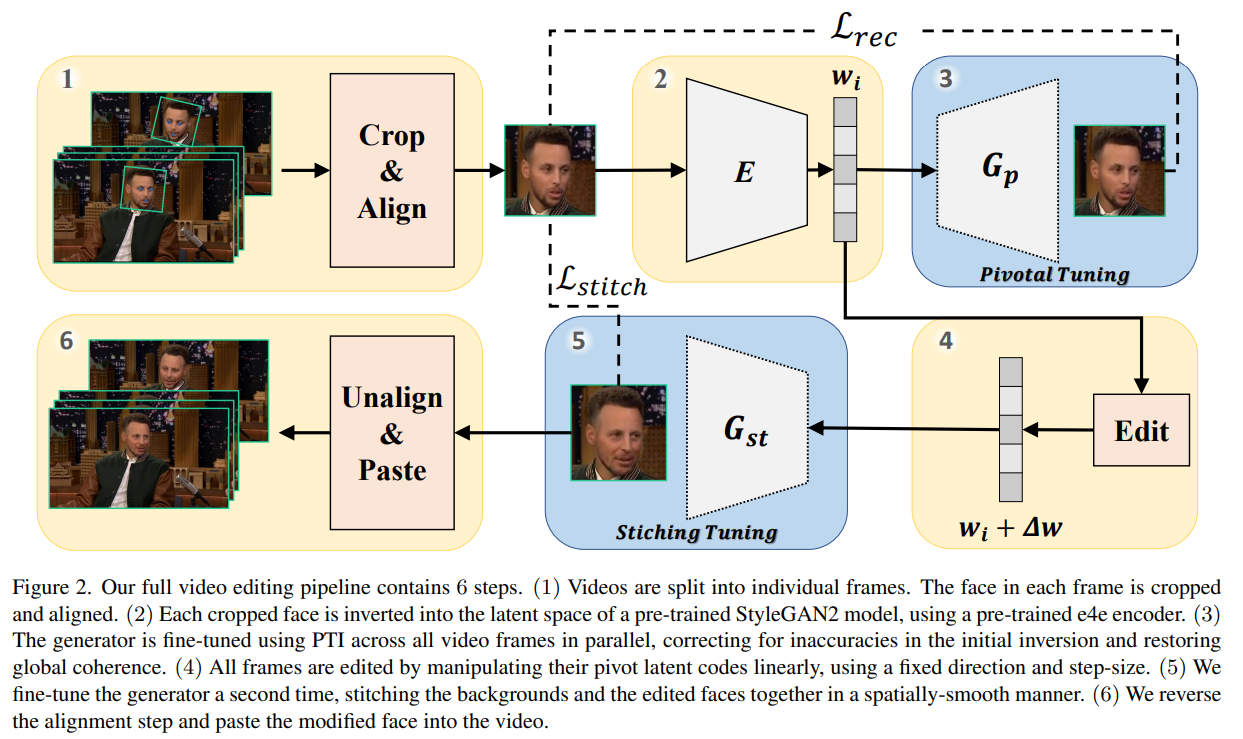
Présentation du modèle. Image tirée du papier.
Ici, ils prendront chaque image de la vidéo comme image d'entrée, extrairont uniquement le visage et l'aligneront (1) pour la cohérence, ce qui est une étape essentielle comme nous le verrons, utiliseront ensuite leur encodeur préentraîné (2) et leur générateur (3) pour encoder les images de la vidéo et produire de nouvelles versions pour chacune d’entre elles. Malheureusement, cela ne résoudrait pas le problème de réalisme où les nouveaux visages peuvent sembler bizarres ou déplacés lorsqu'ils passent d'une image à l'autre dans la vidéo finale, ainsi que des bogues d'éclairage étranges et des différences d'arrière-plan.
Pour résoudre ce problème, ils entraîneront davantage le générateur initial (3) et l'utiliseront pour aider à rendre les générations de toutes les images plus similaires et globalement cohérentes. Ils introduisent également deux autres étapes, une étape d'édition et une nouvelle opération qu'ils appellent "stitching-tuning".
L'étape d'édition (4) prendra simplement la version encodée de l'image et la modifiera un peu. C'est la partie où le réseau apprendra à changer l’encodemment juste assez pour faire paraître la personne plus âgée, par exemple. Ainsi, le modèle sera formé pour comprendre quels paramètres déplacer et dans quelle mesure modifier les bonnes caractéristiques de l'image pour faire paraître la personne plus âgée. Comme ajouter des cheveux gris, ajouter des rides, etc.
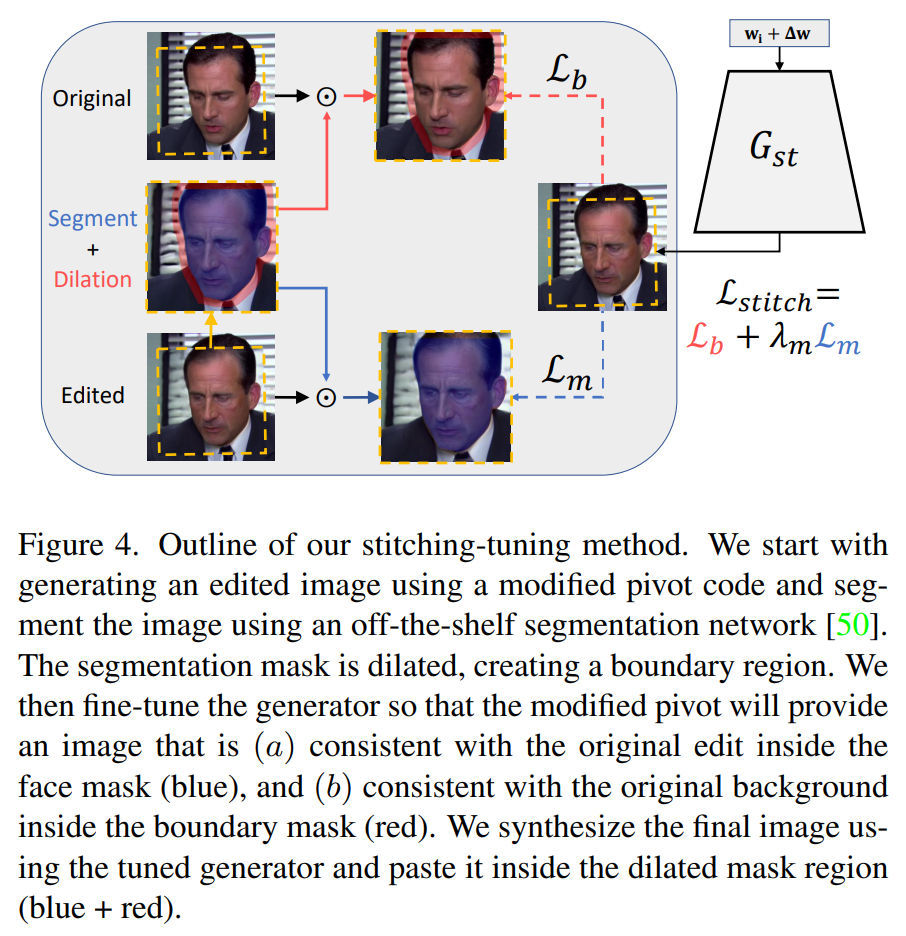
L'étape 5 en détail : La méthode d'assemblage-réglage. Image tirée du papier.
Ensuite, cette méthode de réglage d'assemblage (5) prendra l'image encodée que vous voyez ici et sera formée pour générer l'image à partir du code édité qui s'adaptera le mieux possible à l'arrière-plan et aux images précédentes et suivantes de la vidéo. Le réseau y parviendra en prenant l'image nouvellement générée, en la comparant à l'image d'origine et en trouvant le meilleur moyen de remplacer uniquement le visage à l'aide d'un masque identifiant uniquement le visage et l’intersection entre le visage et l’arrière-plan et conservera le reste de l'image recadrée inchangée.
Enfin, nous collons le visage modifié sur l’image de la vidéo (6) et répétons ce processus pour toutes les images d’une vidéo. Ce processus est assez intelligent et permet la production de vidéos de très haute qualité puisque vous n'avez besoin que du visage recadré et aligné dans le modèle, ce qui réduit considérablement les besoins de calcul et la complexité de la tâche. Donc même si le visage doit être petit, disons 200 pixels carrés, comme vous pouvez le voir ici, si ce n'est qu'un cinquième de l'image, vous pouvez garder une vidéo assez haute résolution pour votre vidéo!
Et voilà ! C'est ainsi que ces chercheurs réalisent des manipulations faciales de haute qualité dans des vidéos !
Merci d'avoir lu, regardez la vidéo sous-titrée en français pour plus d'exemples !
Références
Tzaban, R., Mokady, R., Gal, R., Bermano, A.H. and Cohen-Or, D., 2022. Stitch it in Time: GAN-Based Facial Editing of Real Videos. https://arxiv.org/abs/2201.08361
Lien vers le projet: https://stitch-time.github.io/