Google résout le défi de la fenêtre contextuelle pour les modèles de langage ?
Regardez le vidéo!
Fenêtre de contexte, ou context window. Ces mots ont probablement été les plus recherchés et les plus attendus dans les articles de recherche sur les grands modèles de langue et les annonces d'OpenAI, Anthropic ou Google. Eh bien, grâce au plus récent article de Google: Infini-attention, les fenêtres de contexte ne sont plus un problème. Voyons comment ils ont accompli cela. Mais d'abord, nous avons également besoin d’un peu de… "contextes" pour comprendre ce qu'ils ont fait.

L’article de Infini-attention
La fenêtre de contexte est une manière élégante de dire combien de mots vous pouvez envoyer simultanément à un modèle de langue (LLM). Plus la fenêtre est grande, plus vous pouvez envoyer de mots, plus le modèle peut saisir le contexte et ainsi, mieux comprendre votre question pour fournir une réponse appropriée.
On souhaite envoyer au modèle autant d'informations que possible et le laisser déterminer la meilleure manière de répondre à nos besoins. Le problème est que les performances des modèles de langage diminuent considérablement à mesure que le contexte s'accroît. Souvent, plus il voit de mots, pires sont les résultats. Si vous donnez à GPT-4 une page de livre et posez une question sur un personnage que vous savez présent sur cette page, il répondra parfaitement. Mais si vous lui donnez tout le livre, il pourrait ne pas être capable de comprendre la question. Le modèle est essentiellement submergé. Je suppose que c'est la même chose pour nous. Imaginez devoir étudier un livre entier pour un examen, et la première question vous demande de vous souvenir d'un détail très spécifique à la page 24. C’est une tâche assez complexe !
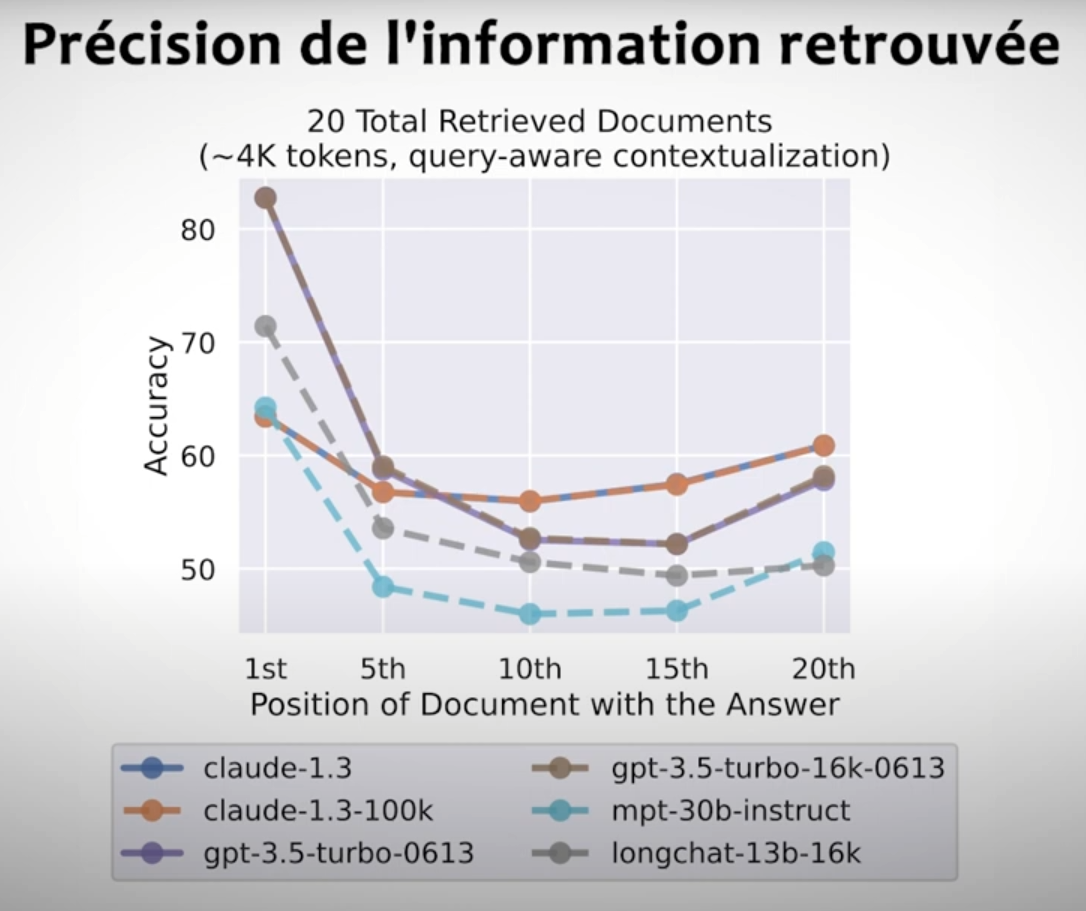
Les performances se dégradent considérablement lorsque les modèles doivent accéder et utiliser des informations situées au milieu/fin de leur contexte d'entrée. Image tirée du papier Lost in the Middle.
Le modèle est simplement submergé par trop d'informations et beaucoup d'informations inutiles. Les idées clés sont diluées avec des tonnes de pages non pertinentes. De plus, il doit traiter toutes ces informations supplémentaires pour rien ! Cela coûte de l'argent réel en termes de mémoire GPU. Non seulement cela, mais des modèles comme GPT-4 ont en réalité une limite stricte sur le nombre de mots, basée sur l'implémentation de l'architecture du modèle, en particulier pour le mécanisme d'attention, que nous avons couvert de nombreuses fois sur la chaîne. De plus, le modèle pourrait ne pas avoir été entraîné pour voir autant de données en une seule fois. Ainsi, il peut prêter attention à quelques mots ou phrases, mais un livre entier pourrait être trop. Il pourrait juste être utilisé pour quelques phrases. C'est comme donner un livre de mille pages à un enfant qui avait l'habitude de lire des bandes dessinées.

Processus d’attention.
Le mécanisme d'attention est l'un des principaux obstacles à l'augmentation de la fenêtre de contexte de nos modèles de langues. Ce type de couche du réseau nous permet de comprendre le contexte entre nos mots. Il apprendra les relations entre les mots pour comprendre si nous parlons d'une banque financière ou du bord d'une rivière, étant le même mot bank en anglais. À travers des millions d'exemples de phrases comme celle-ci, ce mécanisme d'attention apprendra à prendre le contexte approprié des phrases pour comprendre le sens de chaque mot. Par exemple, ici pour se concentrer sur le fait que quelqu'un est assis dessus, ce qui pourrait être faisable, mais compliqué pour une banque financière.


Mots vs. Tokens.
Plus nous étendons cette phrase, plus la tâche devient difficile et plus nous avons besoin de calculs, car nous comparons chaque mot avec tous les autres. D'ailleurs, pour simplifier, je parle ici de mots, mais en réalité, cela fonctionne avec des tokens, qui sont des représentations numériques de nos mots, ou plutôt de parties de mots, pour rendre cette comparaison mathématiquement possible. Étant des êtres intelligents, nous comprenons cela à travers le contexte de la phrase, mais en tant que machine, elle doit le calculer avec des vecteurs et des mathématiques.
Ce calcul est difficile à effectuer en une fraction de seconde avec une grande efficacité, surtout si nous étendons le texte à un livre ou même à plusieurs manuels. Eh bien, Google a rendu l'utilisation du mécanisme d'attention beaucoup plus gérable pour de tels grands contextes de millions de mots grâce à leur nouvel article et approche : Infini-attention.
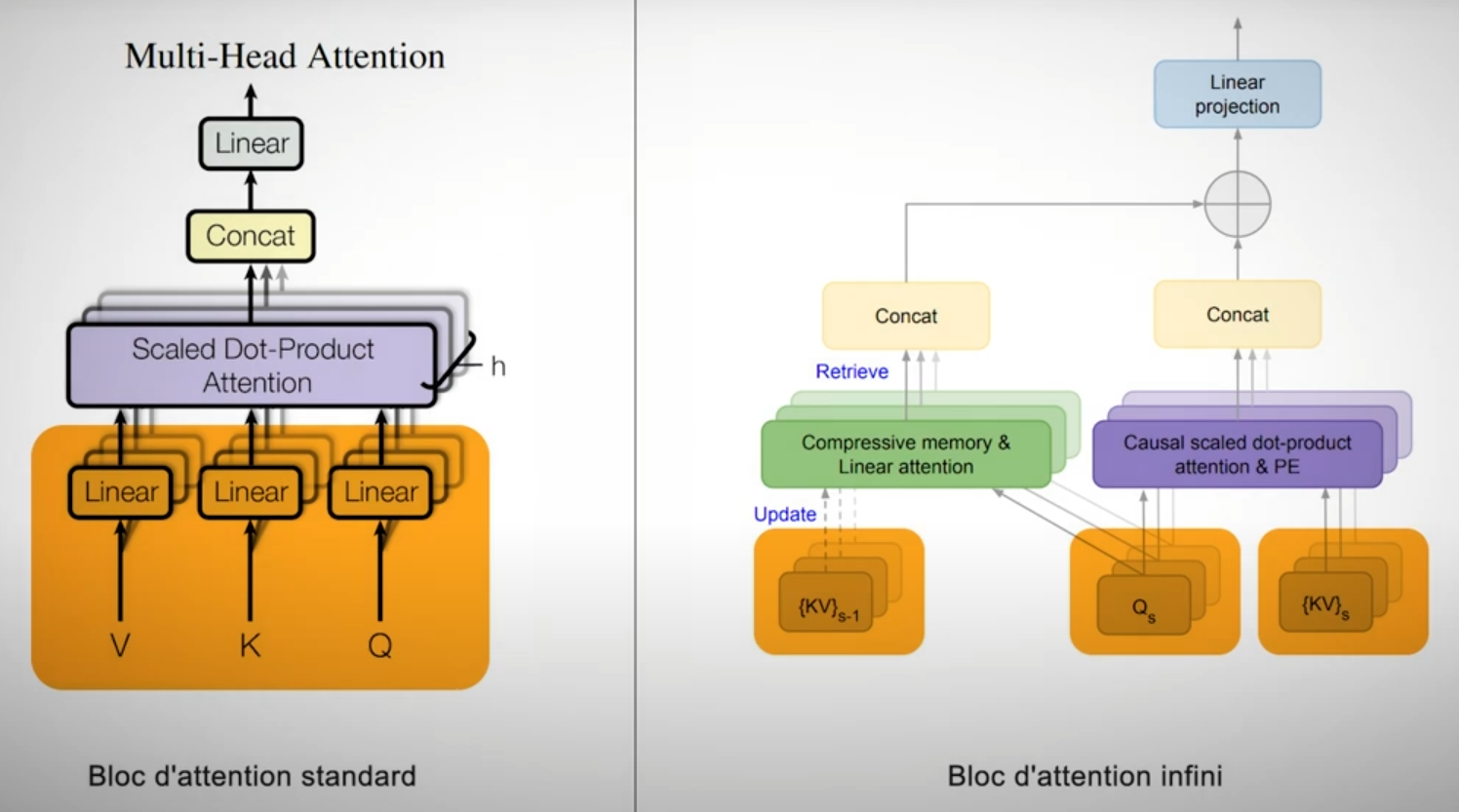
Processus d'attention (à gauche) et processus d'attention infinie (à droite) avec un bloc d'attention distinct pour les longues et courtes portées. Image adaptée de l’article Lost in the Middle.
Infini-attention modifie le mécanisme d'attention standard en divisant le calcul en deux parties distinctes : une pour les informations locales, se concentrant sur les mots proches, et une autre pour les relations à longue distance, reliant les mots et idées qui sont significativement plus éloignés dans le texte. Une amélioration majeure de ce modèle est sa capacité à transformer le coût computationnel de quadratique à linéaire par rapport à la longueur de la séquence en entrée, grâce à des modifications clés du mécanisme d'attention, incluant l'introduction d'une mémoire compressive.
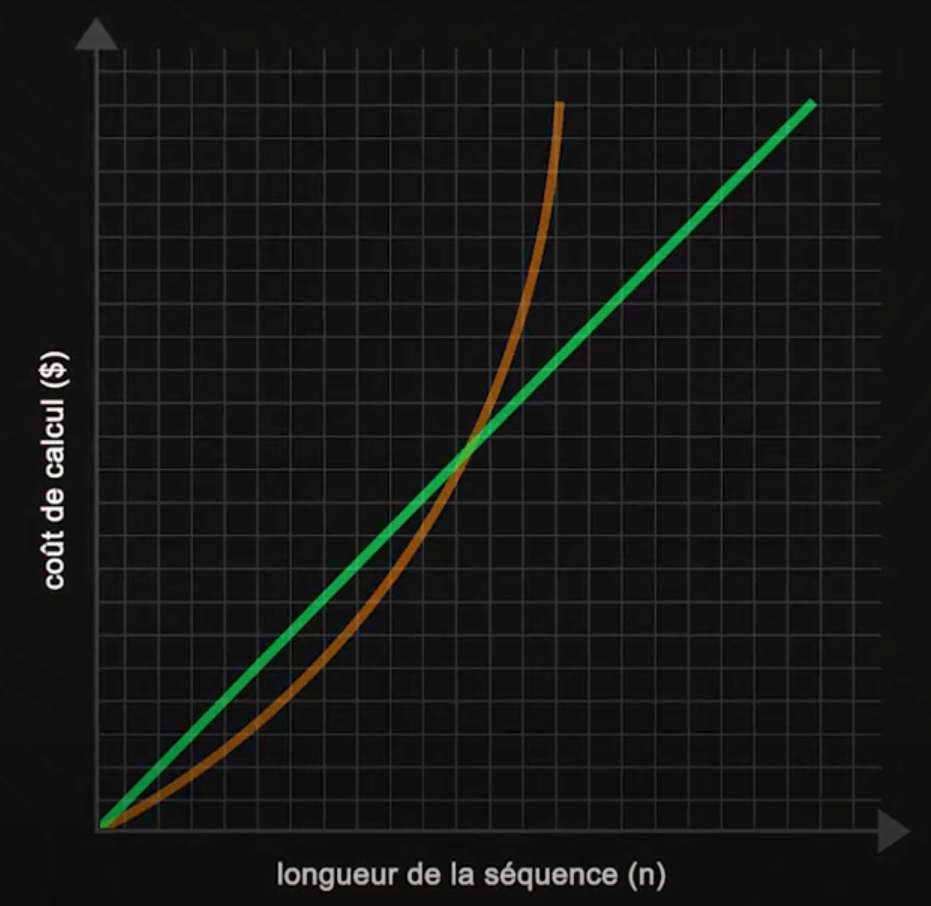
Fonction quadratique (orange) et linéaire (verte).
Initialement, Infini-attention traite le texte par segments plutôt que l'ensemble du contexte simultanément, en calculant l'attention locale au sein de ces segments individuels. Au-delà du simple traitement de segments individuels, le modèle compresse les informations des segments passés dans sa mémoire, facilement accessible pour les besoins futurs. Cette méthode permet l'intégration efficace du contexte à longue portée dans chaque calcul local, ce qui améliore considérablement le potentiel d’évolution et la densité du traitement des données.

Séquençage du Transformer-XL (transformeur original) pour les entrées longues.
Cette approche signifie qu'au lieu de recalculer continuellement la pertinence des données anciennes à chaque fois qu'une nouvelle entrée est traitée, le modèle stocke efficacement cette information sous une forme compressée. Lorsque le contexte de ces segments passés redevient pertinent, le modèle peut le récupérer rapidement de cet mémoire compressée. Ainsi, lorsque le modèle traite un nouveau segment de texte, il ne repart pas de zéro. Il récupère les informations pertinentes de sa mémoire compressée en fonction des requêtes d'entrée actuelles, en mettant en avant les données historiques les plus pertinentes. Cela garantit que même les détails distants mais pertinents sont pris en compte à chaque nouvelle étape.

Séquençage avec l’Infini-Transformer pour les entrées longues avec mises à jour et récupération de mémoire compressives.
Après avoir traité chaque segment, le modèle met à jour sa mémoire, en incorporant de nouvelles données et en écartant sélectivement les informations moins pertinentes. Cela permet de garder la mémoire efficace et gérable, optimisant à la fois la performance et l'utilisation des ressources.
Et voilà ! En gérant la mémoire de cette manière, Infini-attention atteint un équilibre entre la profondeur du contexte et l'efficacité computationnelle, ce qui est crucial pour les tâches impliquant de grands volumes de texte ou lorsque le contexte historique influence significativement les décisions actuelles.
Ils ont démontré que le mécanisme Infini-attention fonctionne même mieux lorsque nous lui donnons plus de contexte, au lieu de détériorer les résultats.
En résumé, c'est un travail très important qui nous permet de donner plus d'informations à notre modèle de langue, comme des manuels complets, afin qu'ils nous fournissent de meilleures réponses et plus appropriées, ce qui signifie que nous travaillons de moins en moins et perdons de plus en plus de neurones ! Plutôt cool, n'est-ce pas ? Je plaisante, bien sûr. Enfin, j'espère que je plaisante et que cela n'arrivera pas…
Bien sûr, c'était juste une d’introduction sur ce nouvel article de recherche et cette approche. L'article s'intitule "Leave No Context Behind" et j'ai ajouté un lien dans la description ci-dessous. Je vous invite définitivement à le lire et à en apprendre davantage sur ce mécanisme et les modèles de langage en général ; c'est une lecture très intéressante.
Merci d'avoir lu l’article jusqu'au bout, et je vous retrouve dans la prochaine !