Les nouveaux modèles d’IA savent-ils enfin raisonner ?
Regardez la vidéo!
Imaginez que vous ouvriez ChatGPT et posiez l’ancienne “question piège” de la fraise : « Combien de R y a-t-il dans le mot strawberry? »
Il y a deux ans, le modèle hallucinait ou, si vous aviez de la chance, devinait correctement une fois sur deux, mais pouvait certainement pas dire où étaient les R dans le mot.
Aujourd’hui, avec les nouveaux modèles de « raisonnement », on appuie sur Entrée et regarde le système réfléchir. On le voit réellement épeler s-t-r-a-w-b-e-r-r-y, compter les lettres, puis répondre « trois ». Cela semble presque magique, comme si le modèle avait soudain découvert l’arithmétique. Spoiler : ce n’est pas le cas. Il a simplement appris à dépenser plus de tokens avant de nous répondre. Et il peut se permettre ce luxe parce que la capacité brute du modèle est passée des 117 millions de paramètres du GPT-2 (ou 1,5 milliard dans sa plus grande variante) qui mâchait huit milliards de tokens à des géants de plusieurs billions de paramètres entraînés sur environ 15 billions de tokens. Pratiquement tout le web lisible, répartis sur des milliers de GPU H100.
Ça c’est le cœur de la toute dernière vague de recherche sur les grands modèles de langage. Pendant des années, nous n’avons vécu que d’une règle—les lois de l’échelle (ou les “scaling lawes”). Des principes selon lesquels plus on les pousse à leur limite, meilleurs sont les résultats. Plus de paramètres de modèle plus plus de données égale plus de compétences. Mais on peut pas grandir indéfiniment : on racle déjà les fins fonds du web et les GPU des centres de données font fondre la couche d’ozone lors de l’entraînement des modèles.
On entre dans ce que de nombreux chercheurs appellent un « plateau de pré-entraînement ».
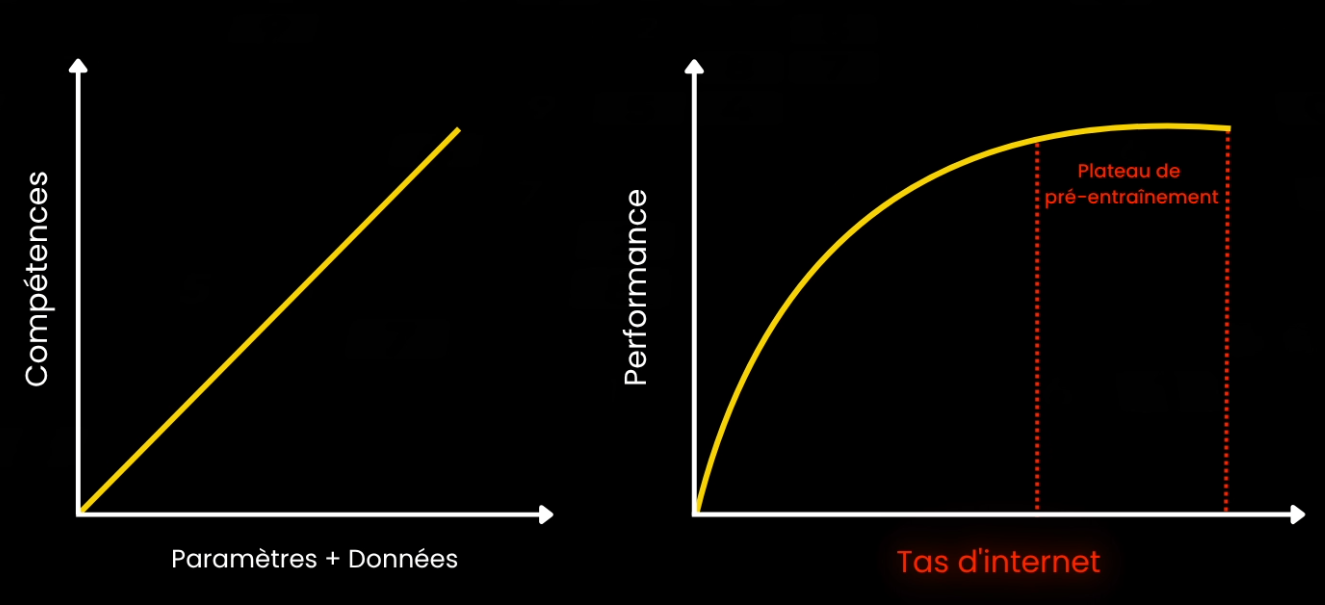
Ainsi, au lieu d’aborder la question de la conscience des modèles, les chercheurs ont demandé : « Et si on ne peut plus faire évoluer le modèle lors de l’entraînement, pourrions-nous plutôt le faire évoluer au moment de répondre? »
C’est ainsi qu’ont vu le jour les modèles de raisonnement : mêmes entrailles neuronales, mêmes poids, mais une nouvelle loi d’échelle au moment de l’inférence. Plus de calcul après que l’utilisateur a cliqué sur Envoyer, avec l’hypothèse que si les résultats sont suffisamment bons, nous, les utilisateurs, accepterons d’attendre quelques secondes, minutes ou même plus.
Voici comment cela fonctionne en pratique.
Un modèle GPT classique produit un token à la fois jusqu’à atteindre un marqueur de fin de texte. Comme ceci. Et il apprend à générer ce token de façon autonome durant son entraînement lorsqu’il a terminé de répondre, puisque nous avons manuellement ajouté ce même token dans tous nos exemples d’entraînement pour lui apprendre à le faire. Si vous êtes déjà perdu, je vous suggère de regarder notre introduction aux grands modèles de langage afin de bien comprendre les tokens et les embeddings, ce qui vous aidera réellement à mieux comprendre et exploiter les LLM en général! On a même récemment sortie un cours de deux heures pour comprendre les fondements des LLMs!
Au lieu de cette génération habituelle de tokens en flux unique de réponse, les modèles de raisonnement en génèrent deux. Il y a d’abord un monologue caché, la chaîne de pensée, qui est en gros la même chose que la technique populaire du chain-of-thought prompting. Les ingénieurs ont littéralement introduit un nouveau token, end-of-thinking, pour marquer l’endroit où ce bloc-notes privé s’arrête. Ce n’est qu’une fois le brouillon refermé que le modèle rédige la réponse polie et émet le traditionnel token end-of-text qui marque la fin de sa réponse. Le modèle n’est pas devenu logique au sens humain ; il prédit toujours le prochain token le plus probable. Il se contente désormais de prédire un préambule plus long, de parcourir la solution pas à pas et augmente ainsi ses propres chances de deviner correctement le token final en s’offrant davantage de contexte, poussant la probabilité en sa faveur un token à la fois.
Et comment obtient-on un tel modèle qui « raisonne »?
Pour obtenir un modèle de raisonnement, vous partez d’un gigantesque modèle pré-entraîné, tel que GPT-4 ou un Gemini. Il suit donc la même étape de pré-entraînement que vous connaissez déjà si vous avez regardé mes vidéos auparavant.
Ensuite, vous constituez un jeu de données où chaque exemple contient une question, une preuve complète sous forme de chaîne de pensée, et la réponse finale. Le code et les mathématiques sont populaires, car les preuves et le code sont vérifiables et binaires : soit le théorème est résolu, soit il ne l’est pas ; soit le programme s’exécute, soit il échoue.
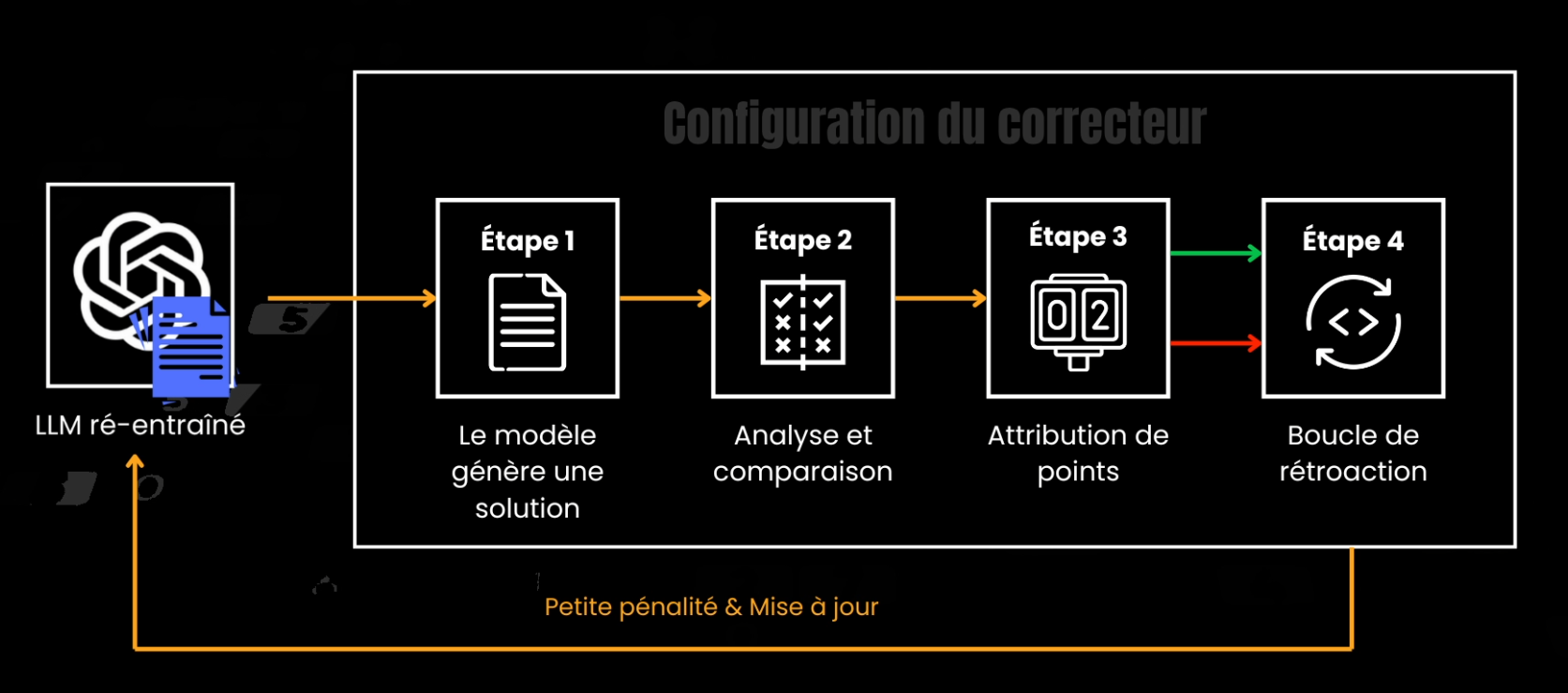
Puis, on injecte ces triplets dans une passe de réentraînement supervisé afin que le réseau apprenne à placer end-of-thinking au bon moment, avant end-of-text. On ajoute ensuite une boucle d’apprentissage par renforcement. Au lieu de récompenser chaque token, on note uniquement la réponse finale à l’aide d’une fonction spéciale ou d’un juge, quiu peut être un autre modèle de langage, un humain, ou un compilateur si la tâche concerne du code. Bonne réponse? Pas de mise à jour des poids du modèle. Mauvaise réponse? Petite pénalité et on change les poids qui ont causés cette mauvaise réponse. C’est très similaire au réentraînement par renforcement qu’OpenAI a récemment annoncé, où une douzaine d’exemples peuvent déjà orienter le style et la structure vers vos objectifs comparé a des milliers d’exemples nécéssaires pour un ré-entraînement classique token par token.
Finalement, on lance une phase d’équilibrage où le modèle s’exerce sur des questions nécessitant zéro, peu ou beaucoup de raisonnement, afin qu’il apprenne quand rester concis et quand consacrer beaucoup de temps (et de calcul) à réfléchir. Exactement comme nous pouvons répondre instantanément à un simple 2+2, mais avons besoin d’un stylo et de papier, voire d’une calculatrice, pour une intégrale plus complexe.
Grâce à tout ce processus d’entraînement, au moment du déploiement, le modèle décide à la volée combien de temps réfléchir. Posez-lui un fait trivial, et il pourra chuchoter une ou deux lignes cachées, marquer end-of-thinking et répondre instantanément. Demandez-lui de concevoir un nouvel algorithme de tri : vous le verrez cogiter pendant soixante secondes, mâchant des centaines de tokens de déductions privées avant de parler. Ce délai coûte de l’argent réel : chaque token de réflexion représente une facturation API et un cycle GPU. Multipliez cela par la boucle d’un agent qui appelle le modèle dix fois, et soudain votre projet perso ressemble à la location d’un petit centre de données. Voilà le revers de notre nouveau vecteur de mise à l’échelle : nous avons remplacé la croissance des paramètres par la croissance du temps d’inférence, et la facture a suivi.
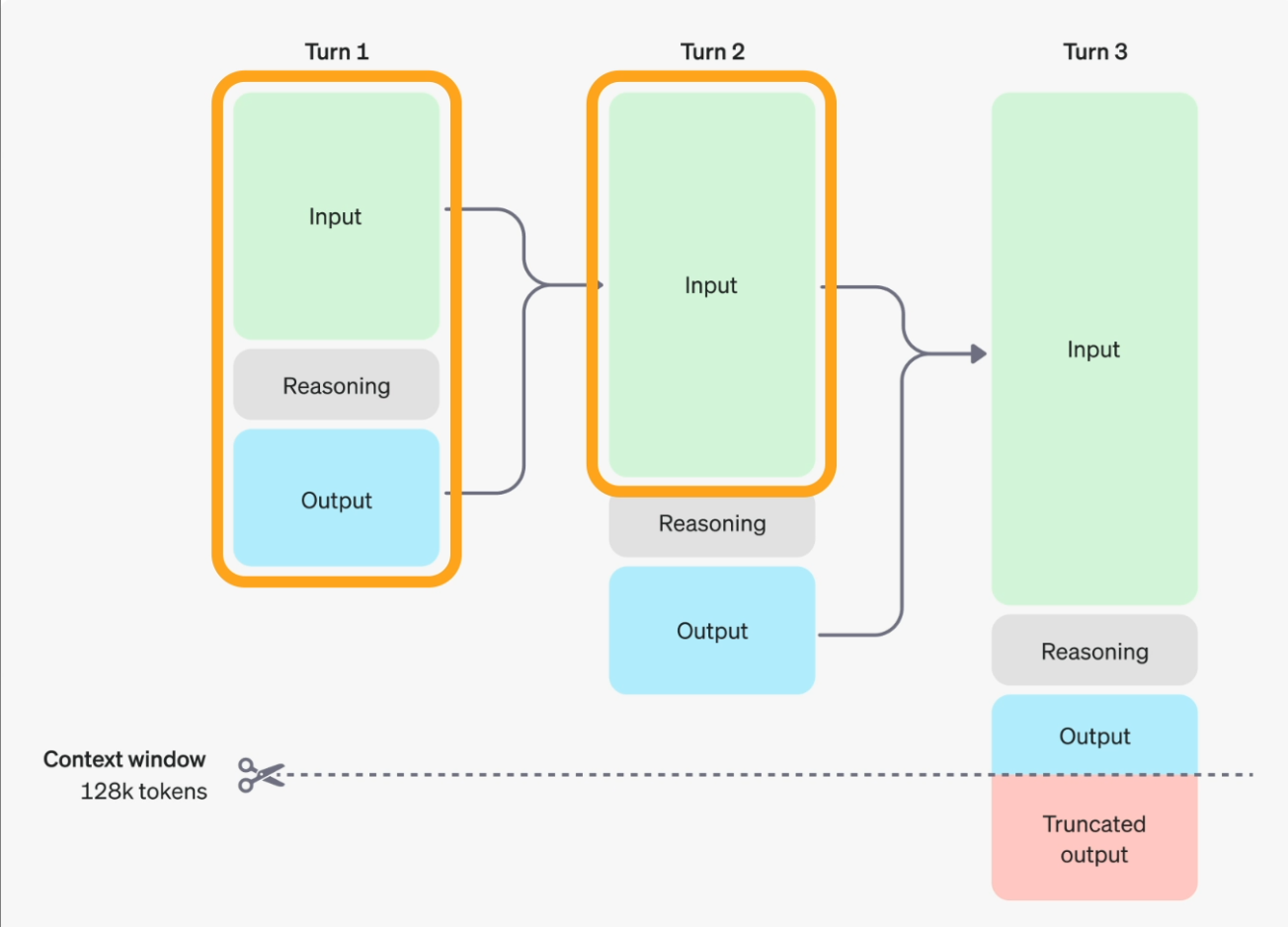
Au fait, OpenAI ne montre pas ce processus de réflexion, alors soyez prudent. Ils n’envoient qu’un résumé contrôlé, qui n’est pas ce que le modèle a réellement produit durant sa réflexion ; vous ne pouvez donc pas l’utiliser pour entraîner votre propre modèle pensant. Ah, et si une partie du raisonnement caché est cruciale pour le tour suivant de la conversation, copiez-la dans votre prompt de suivi, car le modèle l’oubliera : ses notes privées ne sont pas automatiquement transmises à la manche suivante!
Les conseils de prompting ont également changé avec ces nouveaux types de modèles. Avec les LLM ordinaires, on disait souvent d’écrire quelque chose comme « Réfléchit étape par étape » ou de lui donner un plan d’action, par exemple « Commence par lister les lettres, puis compte les R ».
Avec les modèles de raisonnement, ce n’est plus nécessaire. La chaîne de pensée est intégrée. Vous devez plutôt lui donner un objectif ainsi que les contraintes et directives essentielles qu’il doit respecter. Il inventera alors les étapes et les actions nécessaires pour accomplir la tâche. Ici donc, plus vous fournissez d’informations sur ce que vous voulez, contrairement à la manière de procéder, mieux c’est. Et si la latence ou le coût vous importent, demandez explicitement une réflexion concise : « Raisonne brièvement en cinq étapes maximum, puis réponds. » Vous payez des tokens ; rendez l’auteur conscient de cela—et faites de même si vous souhaitez une réponse très approfondie! Malheureusement, y’a pas moyen de contrôler la taille de sorties plus que ça.
Maintenant, quel est le lien entre tout cela et les fameuses lois de l’échelle dont nous sommes partis dans cet article? Imaginez l’échelle classique comme deux axes : paramètres et données. Nous les avons étirés jusqu’à heurter des murs physiques—factures d’électricité, transistors gros comme des atomes, tas de texte neuf qui rapetisse. Les modèles de raisonnement ajoutent un troisième axe que l’on appelle le calcul en temps de test, ou temps d’inférence. Au lieu d’acheter un seau plus haut ou de le bourrer avec plus d’internet, nous secouons le seau plus longtemps chaque fois que nous y puisons quelque chose. C’est un hack astucieux, mais il obéit aussi à la loi des rendements décroissants. Les premières expériences—O1 d’OpenAI, R1 de DeepSeek—montrent de grands gains sur les benchmarks de maths et de code avec un raisonnement supplémentaire modéré. Doublez encore le bloc-notes, et la courbe s’aplatit. À terme, vous nourrissez le modèle de tant de ses propres tokens que vous ne pouvez plus le pousser vers une meilleure réponse s’il ne la connaissait pas déjà dans sa base de connaissances. Ce qui relie cet axe de mise à l’échelle à un autre : l’usage d’outils, et donc, les agents, que nous allons abordés dans une autre vidéo prochainement.
Et abordons l’éléphant dans la pièce : cela signifie-t-il que les machines « raisonnent » enfin? Pas plus qu’hier. Elles restent des prédicteurs de tokens successifs : des machines statistiques extrêmement puissantes qui prédisent un token à la fois. La logique apparente qu’elles semblent acquérir vient simplement d’un échantillonnage plus poussé de probabilités conditionnelles, et non d’une manipulation de symboles ou de modèles causals du monde réel. La chaîne de pensée aide le modèle à exposer des états intermédiaires auparavant cachés, rendant la supposition finale plus fiable et plus facile à auditer pour les humains. Mais sous le capot, chaque étape reste le même jeu statistique que nous jouons depuis GPT-2—bouclé plus longtemps, avec plus de données et plus de calcul.
Où cela nous mène-t-il? À plus d’options et plus de potentiel. Pour des réponses simples de support client, restez sur de petits modèles plus rapides. Pour des questions de recherche complexes ou une génération de code en plusieurs étapes, louez un modèle de raisonnement, prévoyez le budget de tokens et profitez de la profondeur supplémentaire. Si vous avez besoin d’encore plus de puissance et de capacités, naviguez sur le web, codez, planifiez des tâches, citez vos sources, construisez un flux de travail avancé, voire un agent qui exploite les modèles de raisonnement et des outils. Mais vous n’êtes pas condamné à n’utiliser que l’un ou l’autre! Dans un système complexe, on combine généralement les modèles de raisonnement comme « cerveau » de l’agent et les modèles sans raisonnement comme « acteurs » exécutant ce que le cerveau leur dit, que ce soit traduire, utiliser un outil ou réaliser des actions spécifiques. D’ailleurs, nous enseignons comment combiner ces modèles (et bien d’autres) dans notre cours axé sur les agents, en partenariat avec mes amis de Decoding ML. Si vous souhaitez en apprendre davantage sur les agents et construire vos propres systèmes agentiques, jetez un œil au cours dans la description ci-dessous.
Gardez simplement un œil sur les factures d’électricité et sur les nouvelles puces accélératrices : quelqu’un doit payer ces secondes GPU supplémentaires, et notre planète aussi. Alors, s’il vous plaît, pour les deux, utilisez le modèle ou la solution la plus simple qui résout votre problème.
Nous avons commencé en comptant les lettres d’un fruit et terminé avec une nouvelle loi d’échelle montrant qu’on peut consacrer un peu plus de temps de calcul à l’inférence pour acheter beaucoup plus de raisonnement. Que ce raccourci nous conduise jusqu’à l’AGI ou nous offre seulement un peu de répit avant le prochain bond matériel reste une question ouverte. Mais pour l’instant, si vous trouvez votre modèle insuffisamment « intelligent », ne vous précipitez pas pour en entraîner un plus gros : laissez-le d’abord penser à voix haute, puis décidez si la réponse valait les tokens supplémentaires!
J’espère que vous avez apprécié cet article. Si c’est le cas, envoyez-la à un ami et partagez le savoir! Merci d’avoir lu au complet, et on se retrouve dans la prochaine!