Qu'est-ce que “Stable Diffusion“ ? (Modèles de diffusion latente expliqués)
Qu'est-ce que tous les récents modèles de génération d'images comme DALLE, Imagen ou Midjourney ont en commun ? Outre leurs coûts de calcul élevés, leur temps de formation énorme et leur impressionnante couverture médiatique partagé, ils reposent tous sur le même mécanisme : la diffusion.
Les modèles de diffusion ont récemment obtenu des résultats de pointe pour la plupart des tâches reliés aux images, y compris du “texte à image” avec DALLE, mais également pour de nombreuses autres tâches liées à la génération d'images, comme l'inpainting d'image, le transfert de style ou la super-résolution d'image.
Par contre, il y a quelques inconvénients : ils fonctionnent de manière séquentielle sur l'ensemble de l'image, ce qui signifie que les temps d'apprentissage et d'inférence sont très longs. C'est pourquoi vous avez besoin de centaines de GPUs pour former un tel modèle et pourquoi vous attendez quelques minutes pour obtenir vos résultats. Ce n'est donc pas surprenant que seules les plus grandes entreprises comme Google ou OpenAI publient ces modèles.
Mais que sont-ils ? J'ai couvert les modèles de diffusion dans quelques articles, que je vous invite à lire pour une meilleure compréhension. Mais, rapidement, ce sont des modèles itératifs qui prennent en entrée du bruit aléatoire, qui peut être conditionné avec un texte ou une image (donc ce n'est pas du bruit complètement aléatoire). Il apprend itérativement à supprimer ce bruit en apprenant quels paramètres le modèle doit appliquer à ce bruit pour aboutir à une image finale. Ainsi, les modèles de diffusion de base prendront un bruit aléatoire avec la taille de l'image et apprendront à appliquer encore plus de bruit jusqu'à ce que nous revenions à une image réelle. Oui, c’est un peu contre-intuitif, mais ajouter du bruit opposé et calculé à un bruit aléatoire va effectivement l’orienter vers une image précise!

Processus d’ajout de bruit passant d’une image à une autre.
Ceci est possible car le modèle aura accès aux images réelles pendant la formation et pourra apprendre les bons paramètres en appliquant un tel bruit à l'image de manière itérative jusqu'à ce qu'il atteigne un bruit complet et soit méconnaissable (image ci-dessus, vue de droite à gauche jusqu’à la vue complètement bruitée avant l’image d’entrée). Ensuite, lorsque nous sommes satisfaits du bruit que nous obtenons de toutes les images, ce qui signifie qu'elles sont similaires et génèrent du bruit à partir d'une distribution similaire, nous sommes prêts à utiliser notre modèle à l'envers et à lui donner un bruit similaire, aléatoire, et utiliser le modèle dans l'ordre inverse pour créer une image similaires à ceux utilisés pendant la formation.
Cette méthode fonctionne extrèmement bien, comme on peut le voir chez DALLE, mais le problème principal est que vous travaillez directement avec les pixels et des données volumineuses comme des images hautes définitions.

Comparaison des résultats entre “stable diffusion“ (gauche) et deux autres approches (droite). Image tirée du papier.
Voyons comment résoudre ce problème de calcul tout en conservant la même qualité des résultats, comme illustré ici par rapport à DALLE.
Comment ces puissants modèles de diffusion peuvent-ils être efficaces sur le plan computationnel ? En les transformant en modèles de diffusion latente. Cela signifie que Robin Rombach et ses collègues ont mis en œuvre cette approche de diffusion que nous venons de couvrir dans une représentation d'image compressée au lieu de l'image elle-même, puis ont travaillé pour reconstruire l'image. Ils ne travaillent donc plus avec l'espace pixel ou les images régulières.
Travailler dans un espace aussi compressé permet non seulement des générations plus efficaces et plus rapides, car la taille des données est beaucoup plus petite, mais permet également de travailler avec différentes modalités. De plus, puisqu'ils encodent les entrées, vous pouvez lui fournir n'importe quel type d'entrée comme des images ou du texte et le modèle apprendra à encoder ces différentes entrées dans le même sous-espace que le modèle de diffusion utilisera ensuite pour générer une image. Alors oui, tout comme le modèle CLIP, un modèle fonctionnera avec du texte ou des images pour guider les générations.
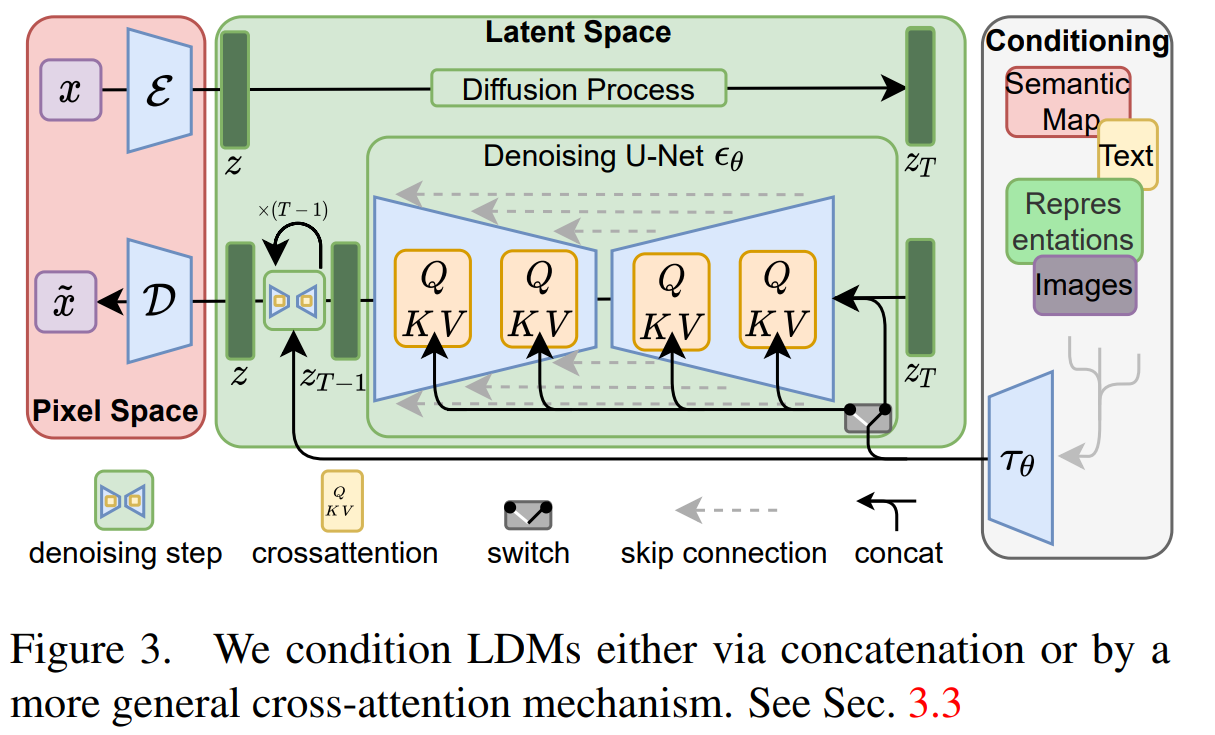
Vue générale du modèle. Image tirée du papier.
Le modèle global ressemblera à ceci : vous aurez votre image initiale ici X, et l'encoderez dans un espace dense en informations appelé l'espace latent, Z. Ceci est très similaire à un GAN où vous utiliserez un modèle d'encodeur pour prendre votre image et extraire les informations les plus pertinentes à son sujet dans un sous-espace, ce que vous pouvez voir comme une tâche de sous-échantillonnage. Réduire sa taille tout en conservant le maximum d'informations.
Vous êtes maintenant dans l'espace latent avec votre entrée condensée. Vous faites ensuite la même chose avec vos entrées de conditionnement, que ce soit du texte, des images ou autre chose (partie droite de l’image du modèle ci-dessus), et les fusionnez avec votre représentation d'image actuelle en utilisant l'attention, méthode que j'ai décrit dans d’autres articles. Ce mécanisme d'attention apprendra la meilleure façon de combiner les entrées et les entrées de conditionnement dans cet espace latent. Nous ajoutons ainsi l'attention, une fonction bien répandue chez les transformeurs, aux modèles de diffusion. Ces entrées fusionnées sont maintenant votre bruit initial pour le processus de diffusion.
Ensuite, vous avez le même modèle de diffusion que j'ai couvert dans mon article sur Imagen, mais toujours dans ce sous-espace.
Enfin, vous reconstruisez l'image à l'aide d'un décodeur que vous pouvez voir comme l'étape inverse de votre encodeur initial. Prendre cette entrée modifiée et débruitée dans l'espace latent pour reconstruire une image haute résolution finale, en suréchantillonnant essentiellement votre résultat.

Images générées utilisant le modèle “stable diffusion”.
Et voilà ! C'est ainsi que vous pouvez utiliser des modèles de diffusion pour une grande variété de tâches telles que la super-résolution, l'inpainting et même le texte à l'image avec le récent modèle open source de diffusion stable à travers le processus de conditionnement tout en étant beaucoup plus efficace et vous permettant de les exécuter sur votre propre GPU au lieu d'en exiger des centaines.
Vous avez bien lu. Pour tous les développeurs ou même pour tous ceux qui veulent tester ce modèle et qui souhaitent avoir leur propre modèle de synthèse de texte en image et d'image fonctionnant sur leurs propres GPU (ou simplement une application), tous les liens et le code sont disponibles avec des modèles pré-formés, et liés ci-dessous !
Si vous utilisez le modèle, veuillez partager vos tests, idées et résultats ou tout commentaire que vous avez avec moi ! J'adorerais suivre tout ça et en parler avec vous!
Bien sûr, ce n'était qu'un aperçu du modèle de diffusion latente et je vous invite à lire leur excellent article lié ci-dessous également pour en savoir plus sur le modèle et l'approche.
References
►Papier : Rombach, R., Blattmann, A., Lorenz, D., Esser, P. and Ommer, B., 2022. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 10684–10695), https://arxiv.org/pdf/2112.10752.pdf
►Code pour “Latent Diffusion” : https://github.com/CompVis/latent-diffusion
►Code pour “Stable Diffusion” (Modèle de texte à image utilisant la diffusion latente) : https://github.com/CompVis/stable-diffusion
►Essayez-le : https://huggingface.co/spaces/stabilityai/stable-diffusion
►Application web : https://stabilityai.us.auth0.com/u/login?state=hKFo2SA4MFJLR1M4cVhJcllLVmlsSV9vcXNYYy11Q25rRkVzZaFur3VuaXZlcnNhbC1sb2dpbqN0aWTZIFRjV2p5dHkzNGQzdkFKZUdyUEprRnhGeFl6ZVdVUDRZo2NpZNkgS3ZZWkpLU2htVW9PalhwY2xRbEtZVXh1Y0FWZXNsSE4