Gen-1, le futur du storytelling ?
L’entreprise à l'origine de l'un des modèles de génération d'images les plus populaires que vous connaissez certainement, Stable Diffusion, a décidé d’aller encore plus loin.
Au lieu de s'attaquer aux images et de produire des résultats incroyables comme ils peuvent déjà le faire, ils sont maintenant sur le prochain défi : les films.

GEN-1. Vidéo du site Web de Runway.
Plus précisément, leur nouveau modèle appelé GEN-1 est capable de prendre une vidéo, comme ce wagon de métro, et de lui appliquer un style complètement différent, instantannément…

Exemple GEN-1. Vidéo du site Web de Runway.
Le modèle est toujours en cours de développement et présente de nombreux défauts, mais effectue un transfert de style assez cool d'une image à une vidéo, ce qui aurait été impossible il y a quelques années, voire quelques mois.
Encore plus cool, ça marche aussi avec du texte. Vous pouvez simplement dire quelque chose comme « un chien avec des taches noires sur un pelage blanc ». Et cela transformera le chien d’une vidéo en celui qui correspond à vos besoins !

Exemple GEN-1. Vidéo du site Web de Runway.
Comme je l'ai dit, c'est définitivement un travail en cours. Nous pouvons voir beaucoup d'artefacts et de comportements étranges, tout comme Stable Diffusion ou ChatGPT. Nous n'avons pas encore résolu le problème. Pourtant, prenez une seconde pour regarder la vidéo ci-dessus. Le modèle n’avait accès qu’à une phrase, et pourtant il a pu comprendre, à partir de cette seule vidéo sans aucune aide ou explication, où le chien était à tout moment et qu'il devait mettre de la fourrure plus blanche ainsi que des points noirs seulement là et nulle part ailleurs. Il a automatiquement isolé le sujet, l'a modifié et l'a remis sur la vidéo. C'est impressionnant.
Ils appellent cette approche "vidéo à vidéo", et il y a encore plus de cas d'utilisation que cette stylisation que nous avons vu comme prendre des maquettes et les transformer automatiquement en rendus stylisés et animés. Rien que la démo ci-dessous de maquette transformée automatiquement me fait penser à toutes les idées que nous pourrions créer très facilement, qui, comme Runway dit, pourraient certainement être "l'avenir du storytelling". J'ai hâte de voir à quoi les résultats ressembleront dans quelques mois. Au fait, vous pouvez demander l'accès au modèle sur leur site Web. J'ai ajouté tous les liens dans les références ci-dessous.

Exemple GEN-1. Vidéo du site Web de Runway.
Mais ce qui est encore plus cool et plus important que de regarder les résultats que nous avons, c'est comment cela fonctionne...
C'est là que vous dites, "mais attendez, ne pourrions-nous pas simplement utiliser le modèle stable diffusion sur toutes les images d'une vidéo, et c'est tout ?" Eh bien, oui et non. Si vous faites cela, vous avez besoin d'encore plus de données d'entraînement pour obtenir de bons résultats, et il y a de très fortes chances qu'il ne soit tout simplement pas en mesure de produire des résultats réalistes, avec des sauts et des téléportations étranges entre les images. Ça reste un très bon point de départ et c'est exactement ce qu'ils ont fait.
Ils partent du modèle de stable diffusion. J'avais déjà couvert ce modèle lors de sa sortie, je vous invite donc à regarder l'article que j'ai fait à son sujet pour en savoir plus sur le processus de diffusion et comment celui-ci fonctionne plus précisément.
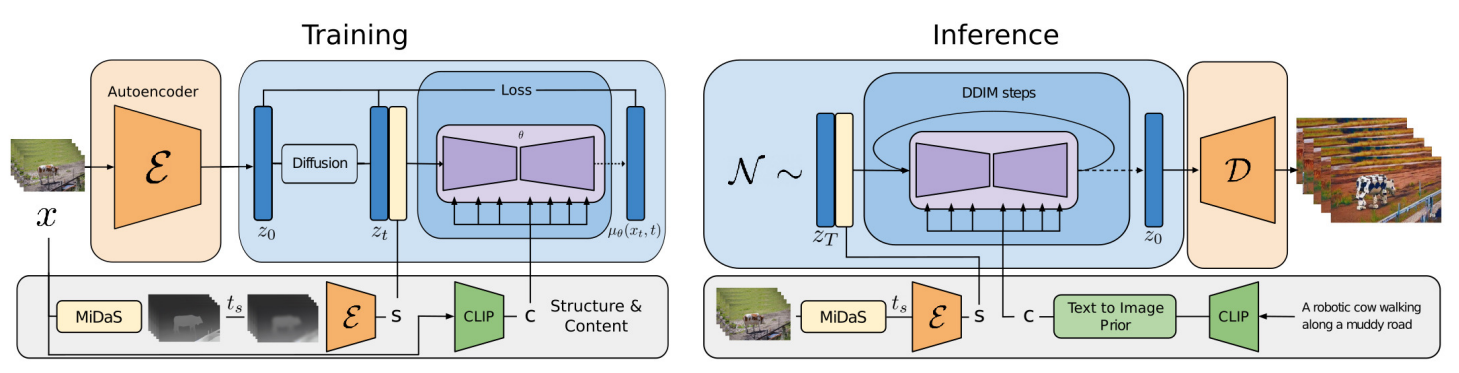
Architecture du modèle Gen-1. L'architecture de formation est à gauche et l'architecture d'inférence (utilisée lorsque la formation est terminée) est à droite.
Nous avons donc un modèle de génération d'images entièrement formé basé sur le processus de diffusion. Il peut déjà prendre des images ou du texte comme entrées pour guider une nouvelle génération d'images. Ici, vous voyez l'architecture complète illustrée comme une séparation d'entraînement et d'inférence, mais notez que la principale différence est l'utilisation d'un encodeur pour traiter une image que vous souhaitez modifier et d'un décodeur pour générer votre image finale, comme nous l'avons vu dans mon article au sujet de stable diffusion. Maintenant, comment pouvons-nous le faire fonctionner avec des vidéos à la place ?
Comme nous l'avons dit, nous ne pouvons pas simplement prendre toutes les images et les traiter une par une pour transformer une vidéo en un autre style, sinon il y aurait des flashs et téléportations constants affectant le réalisme.
Au lieu de cela, nous devons adapter l'architecture avec une sorte de compréhension du temps et de la façon dont les objets de la vidéo évoluent au fil du temps afin que le modèle puisse apprendre à reproduire ce processus. Comment peut-on faire ça?
Pour le problème de cohérence entre les images, ils décrivent leur approche pour diviser une vidéo en contenu et en structure. La structure serait toutes les formes, objets ou sujets de la vidéo ainsi que leurs mouvements dans le temps. Vous pouvez voir maintenant que formuler le problème comme celui-ci devient beaucoup plus facile que d'éditer des “vidéos” ; nous devons maintenant strictement éditer le contenu et garder la même structure.
Cela signifie que la vidéo que nous voulons transformer ne sera utilisée que comme information structurelle, et l'invite de texte ou l'image envoyée comme style à appliquer ne sera utilisée que pour la partie contenu. Cela se fait à l'aide de deux sous-modèles. Nous envoyons initialement la vidéo dans le premier sous-modèle appelé MiDaS, un modèle pré-formé capable d'extraire des cartes de profondeur à partir desquelles nous obtenons nos informations structurelles. Fondamentalement, une carte de profondeur contient toutes les formes, profondeurs et informations que nous voulons conserver de la vidéo.

Une carte de profondeur pour un cube 3D.
Cette étape supprimera automatiquement toutes les informations liées au contenu de la vidéo, ce qui n'est pas utile si nous voulons transférer son style et permet au modèle de se concentrer sur les informations structurelles. Enfin, nous utilisons un autre modèle appelé CLIP qui va extraire nos informations de contenu des l’image ou du texte envoyé. CLIP est souvent utilisé pour extraire des significations du texte ou des images car il a été formé sur les deux pour trouver la meilleure façon de comparer une image avec sa légende. Cela signifie qu'il est assez bon pour "comprendre" ce qui se passe dans une image ou une phrase, qui peut également être considérée comme un contenu ou un style d'image.
Vous avez maintenant vos informations de contenu et de structure pour envoyer la même architecture de diffusion que stable diffusion, mais adaptée pour les vidéos avec une dimension supplémentaire, pour enfin générer notre nouvelle vidéo ! Pour ceux qui veulent des détails supplémentaires, ajouter une dimension pour le temps se fait en ajoutant une convolution unidimensionnelle après chaque convolution du modèle stable diffusion d'image. Ils ajoutent également des encodages positionnels pour savoir quand se trouve chaque image (frame de vidéo) et aider le modèle à comprendre la vidéo. Ces deux ajouts contribueront grandement à la cohérence dans le temps et supprimeront les artefacts étranges que nous avons mentionnés.
Et voilà ! C'est ainsi que vous pouvez prendre une vidéo et transformer complètement son style tout en gardant les objets et les sujets relativement les mêmes ! Je suis excité de voir à quoi cela ressemblera dans deux ou trois publications scientifiques!
Limites:
- A encore quelques incohérences entre les images de la vidéo produite, mais bien mieux que les approches précédentes.
- Ne respecte pas complètement les informations structurelles.
- La vidéo générée n'est pas entièrement réaliste. A les mêmes artefacts que stable diffusion.
Bien sûr, ce n'était qu'un aperçu du nouveau modèle Gen-1 de Runway. Je vous invite à lire leur article scientifique pour une compréhension plus approfondie et à demander l'accès pour l'essayer par vous-même. J'espère que vous avez apprécié la lecture, et je vous verrai la prochaine fois avec un autre papier incroyable!
Références
►Plus d’exemples et demandez l’accès au modèle: https://research.runwayml.com/gen1
►Esser et al., 2023: https://arxiv.org/abs/2302.03011
►Ma Newsletter (en anglais): https://www.louisbouchard.ai/newsletter/